Machine Learning Lecture 8 Auto Encoding
Machine Learning Lecture 8 :: Auto-Encoding
Revisit: Self-supervised Learning Framework
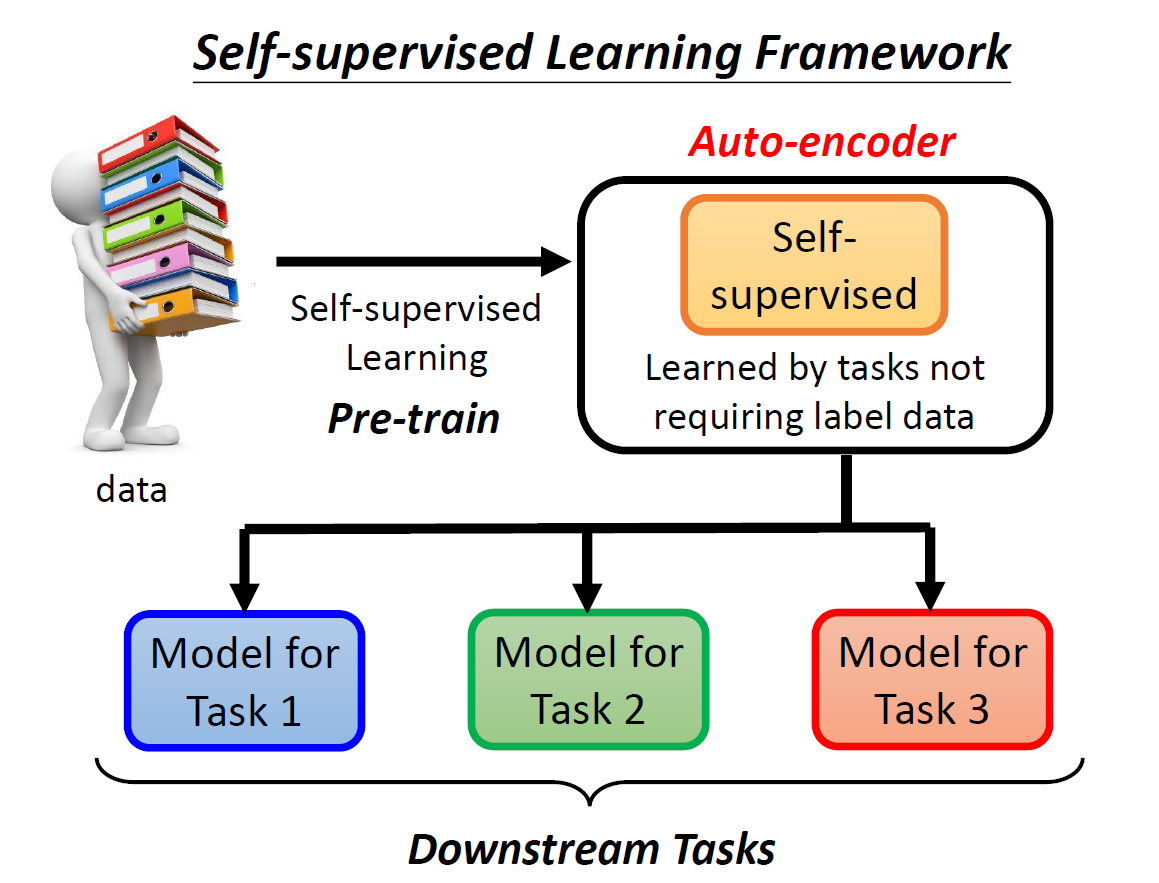
回忆一下之前的 Self-Supervised Learning ,我们有:
data都没有加上标签(untagged)。- 我们直接把资料丢给模型,然后训练。
- 最后将得到的模型运用在一系列的下游任务中。
这样得到的就是所谓的 Self-Supervised 模型,又称 Pre-train 。
Why add auto-encoder?
加入 auto-encoder 的目的,就是为了进一步地调整 pre-train ,从而使其能够更加适用于我们的下游任务,从而使得任务完成的更加精准。
Basic Idea of Auto-encoder
想象我们有一个任务:
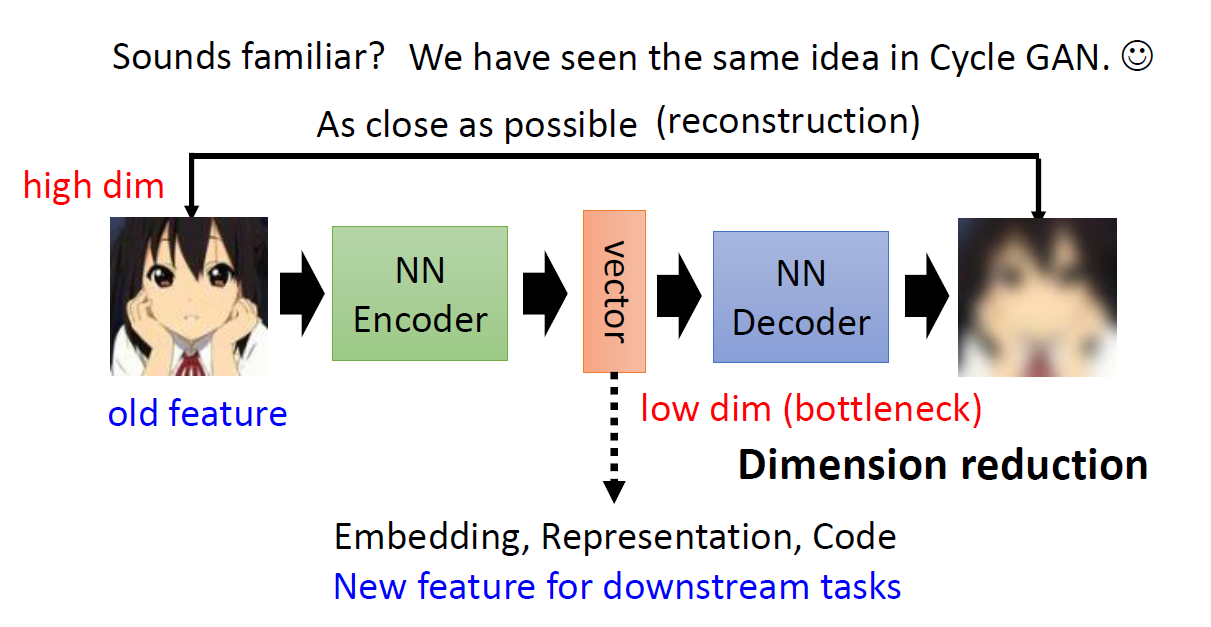
- 我们有一堆 untagged 的图片。可以想象,这些图片相当于一个非常长的向量。即
high-dimension。 - 我们的目标是,通过一系列处理,最后得到一张和原来图片相似的图片。
所以,该怎么做?
Step #1: pic2vec
图片通常是 RGB 三通道 + 像素点,将其压扁后,可以想象成一个非常长的 vec 。我们期望把这个长 vec 变成一个短的 vec ,并且短的 vec 还要能包含一些关键的信息,这样我们才能拿它做一些我们想做的事情。
这个步骤就是,将图片丢进上图中的 NN-Encoder 中,从而得到 vector 。
这个所谓的vector就是我们的低维度 vec 。又称为
Enbedding,Representation,Code。这个vec还包含着一些新特征,这些新特征也可以运用到下游任务中。
Step #2: vec2pic
我们得到了一个 low dim 的向量。我们期望依靠这个向量来重建之前输入的图片。使其越接近越好。
这个步骤也就是将 vector 丢进 NN-decoder 中,从而重建图片。
这很像我们之前所了解的
Cycle-GAN。
Step #3: Compare two pic
最后就是对两个图片进行比较,从而得出 loss function 。
Why Auto-encoder?
所以为什么我们想用 Auto-encoder 技术来降低一个图片的维度呢?为什么可以把一个 3 * 3 的图片转化为 2 * 2 然后又转化成 3 * 3 的图片呢?
- 我们相信说,虽然原始图片是一个很长很长的向量,但是这些向量中的每个元素不一定都是有用的。只要在相应的位置填上数字,我们就能够得到一张图片。
- 因此,我们才可以进行所谓的维度压缩。将一个大维度的图片压缩成一个
vector,从而使得这个vector包含着图片的精华信息。
$\rightarrow$ 所以,使用一个低维的 vector 代表原来的图片,又有什么好处?
这就是所谓的“化繁为简”。我们可以通过简化 vector的方式,以期望在下游任务中,只需要比较少的资料就能完成任务。
An application: De-noising Auto-encoder
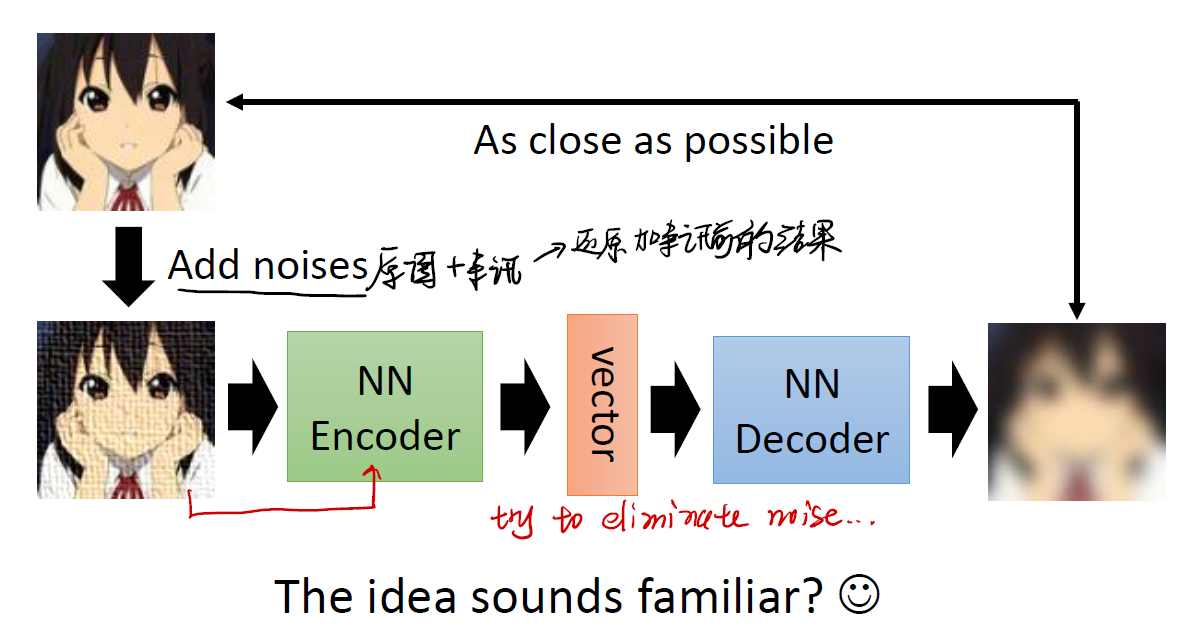
一个典型的应用是将有杂讯的图片通过 auto-encoder 还原成之前的图片。利用 encoder 获取图片的精华信息,剔除图片的杂讯,再利用 decoder 来将其还原成没有杂讯的图片。
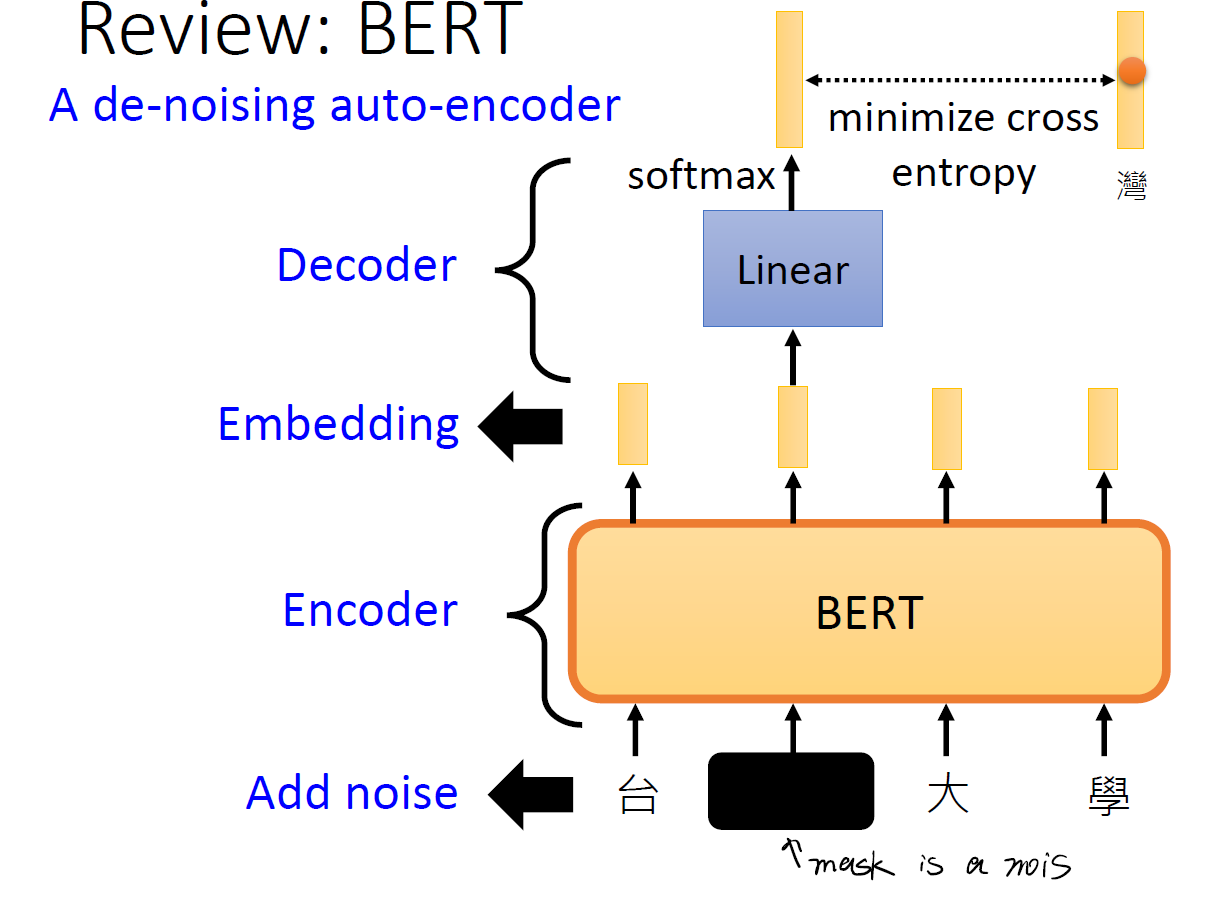
或许,之前我们提到的 Bert 也是如此……
在 Bert 中,我们使用了一个 mask 的做法,将某些字段掩盖起来。这种掩盖其实就是一个所谓的 noise 。
Feature Disentanglement
所谓的 Disentanglement ,意即“将复杂的东西解开”。这是什么意思呢?可以看以下的几个例子:
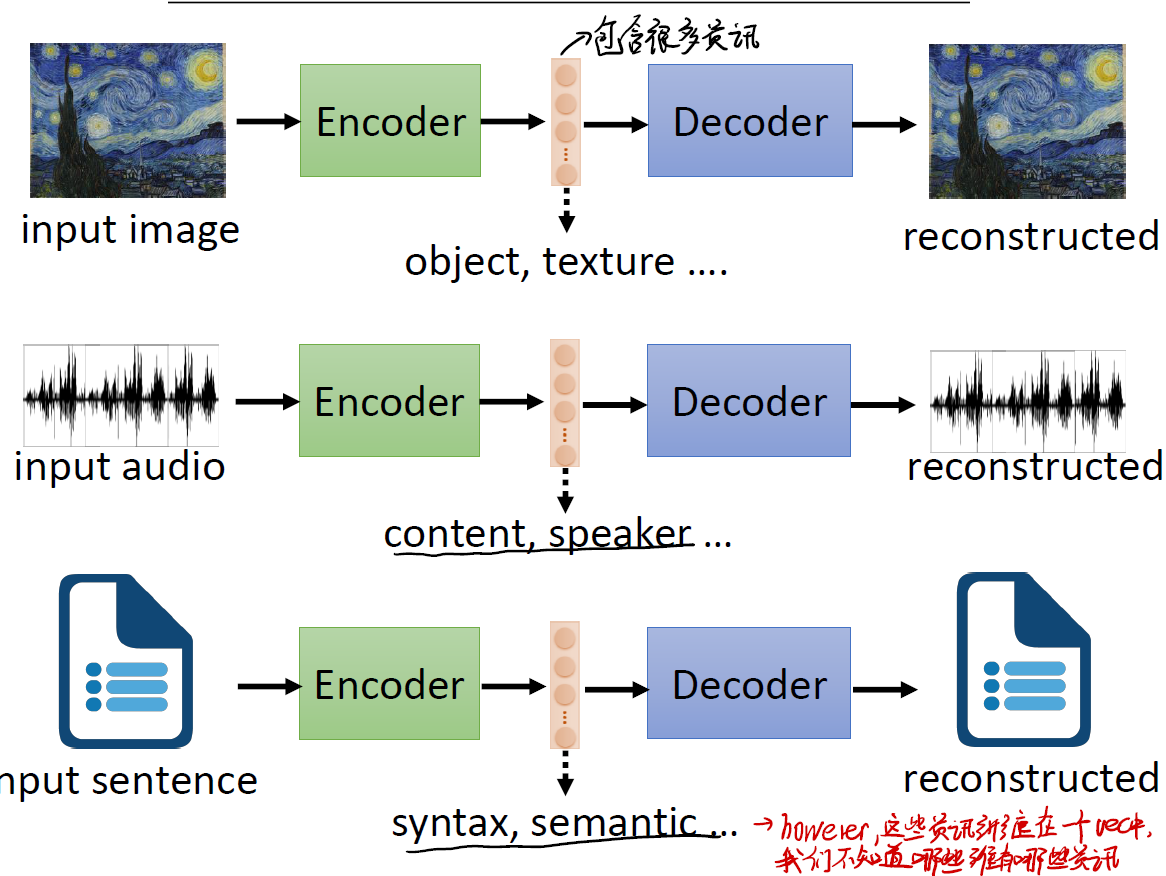
- 在第一个例子中,我们有一张图片。即使我们通过
Encoder技术得到了一个精简短小的 vector ,但这个 vector 中可能还是包含着很多的杂讯,我们或许可以再进一步,从 vector 中提取出图片的纹理、色彩等等重要信息。 - 在第二个例子中,我们有一段声音讯号。同样地,我们也可以在产生的 vector 中寻找我们期望知道的信息。例如谁说的这一段话,这一段话是什么意思等等。
- 在第三个例子中,我们有一段文字输入。我们期望提取出文字的语义、文字的语法等信息。
这一系列信息,都蕴含在一个“小小的” vector 当中。我们期望通过一些方法,在这个 vector 中找到纠缠在一起的信息,并将其分离开。
例如:
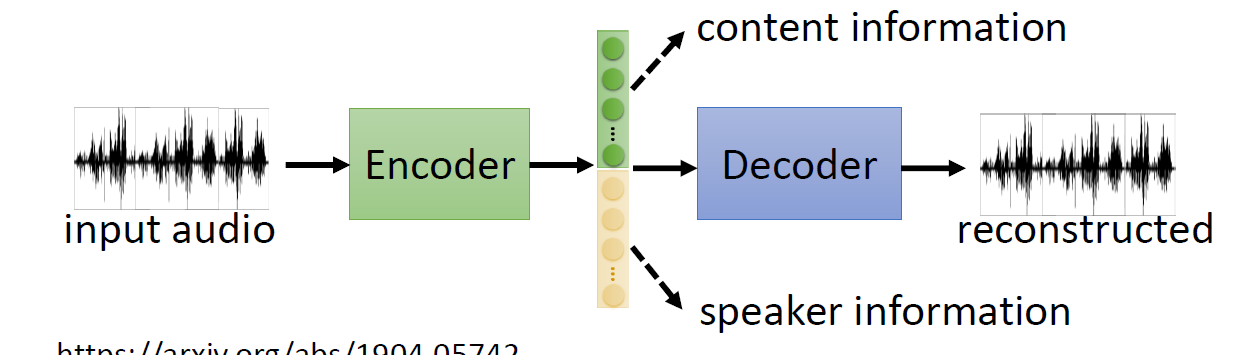
像这样,我们能提取出小 vector 中的有用部分,从而进行组合。
An application: Voice Conversion
这个应用叫做语者转换。即给模型一段话,让其用一个人的声音说出来。
我们期望做到:

- Speaker A 不一定要说一模一样的话。
- Speaker B 可以通过 Speaker A 的话,模仿ta的音色。
怎么做?
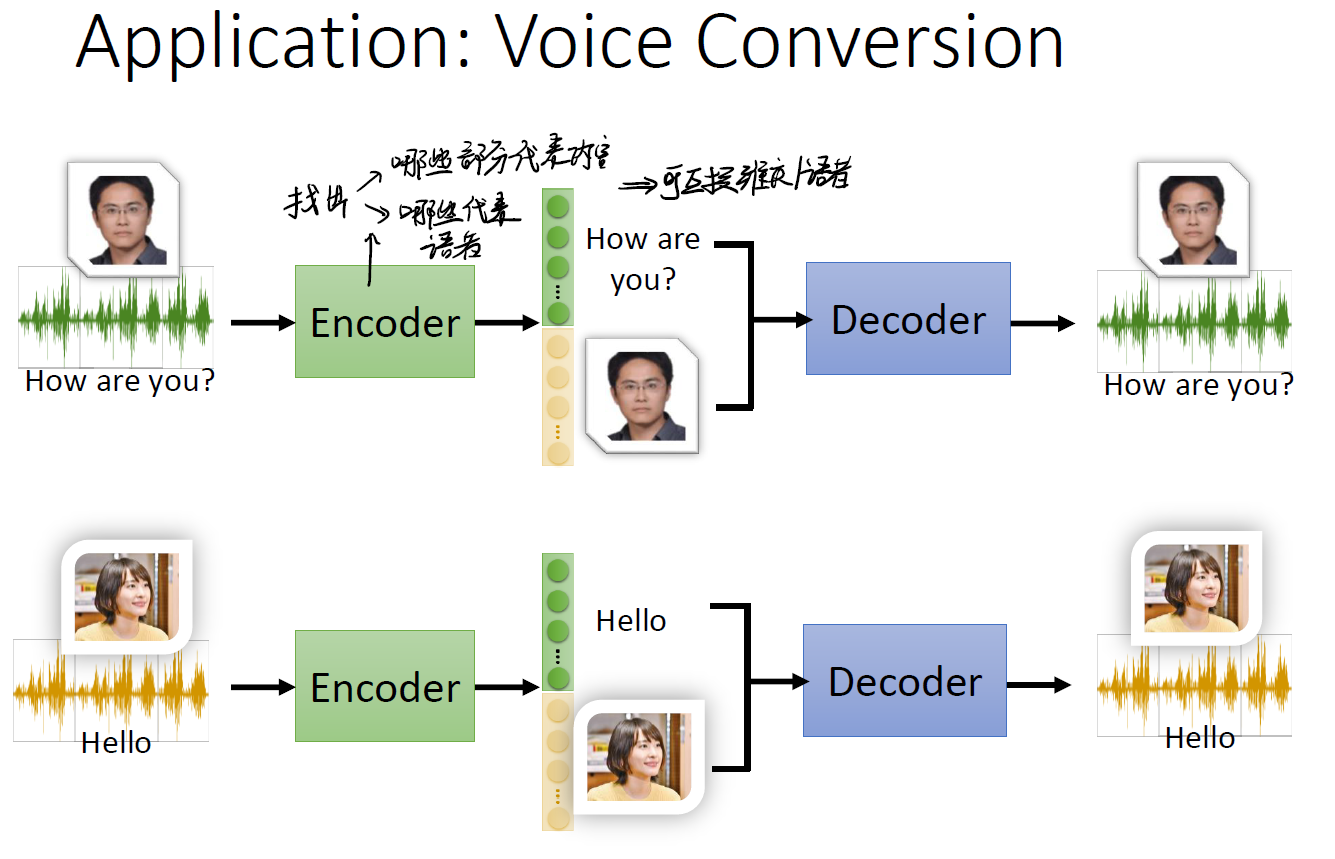
我们以上面的例子来做说明。
- A 说话,我们利用 Encoder ,找出在短小的 vector 中,哪一段是表示
语义的,哪一段是表示语者(即说话的音色)的; - B 说话,我们也将其分割得到两部分。一部分是语义一部分是语法;
- 这样我们可以互相拼接!我们可以让 B 用 A 的音色说话,也可以让 A 说出 B 的内容。
这就是所谓的 Disentanglement 。将不同的资讯从小的 vector 中剥离出来。
Discrete Latent Representation
之前我们设想的那个短小的 vector 我们默认其中的值都是连续的实数。如果,我们要求 vector 中的值是离散的整数呢?
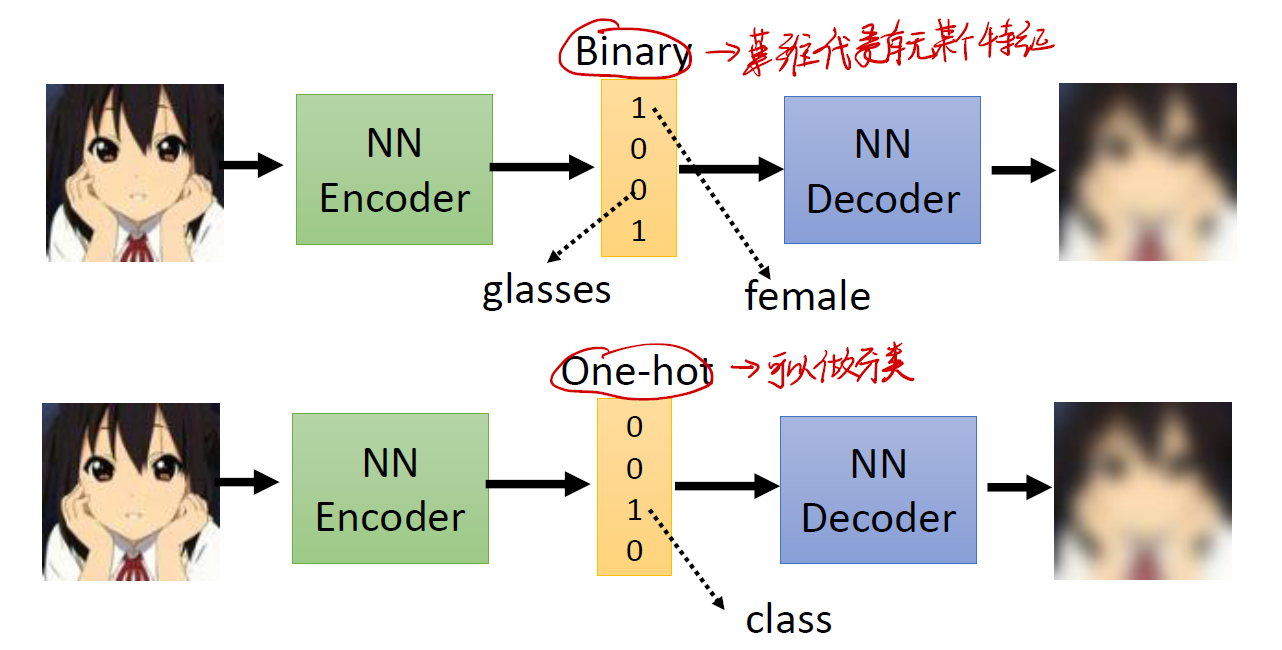
- 如果 vector 中的值是 binary 的,我们可以让其表示图片中是否有某个特征,如图片是否有眼睛,图片中人物的性别是男是女等等。
- 如果 vector 中的值是 one-hot 的,我们可以让其对图片分类。
所以,我们该怎么完成这个任务?
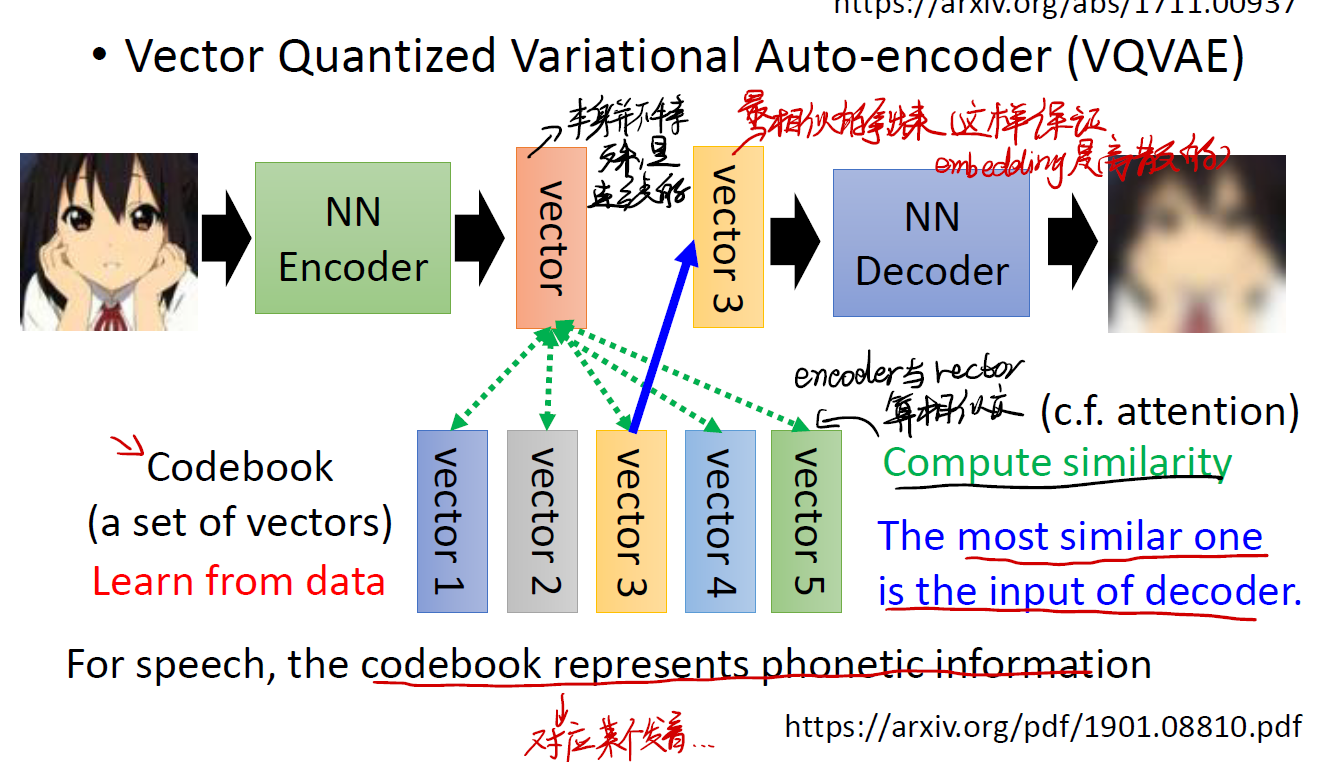
以上图的任务为例。
- 还是利用 Encoder ,得到一个 vector 。需要注意,这个 vector 本身不是什么特殊的 vector ,它其中的值都是连续的。
- 但是我们并不是简单地将其交给 decoder !我们这时候要维护一个 codebook ,里面包含着我们从数据中学习到的特征向量。我们将 vector 与 codebook 中的向量进行相似性比较。谁最相似,谁就作为 decoder 的输入。
- 这样我们就完成了连续 vector 转变成离散 vector 。
An application: Text as Representation
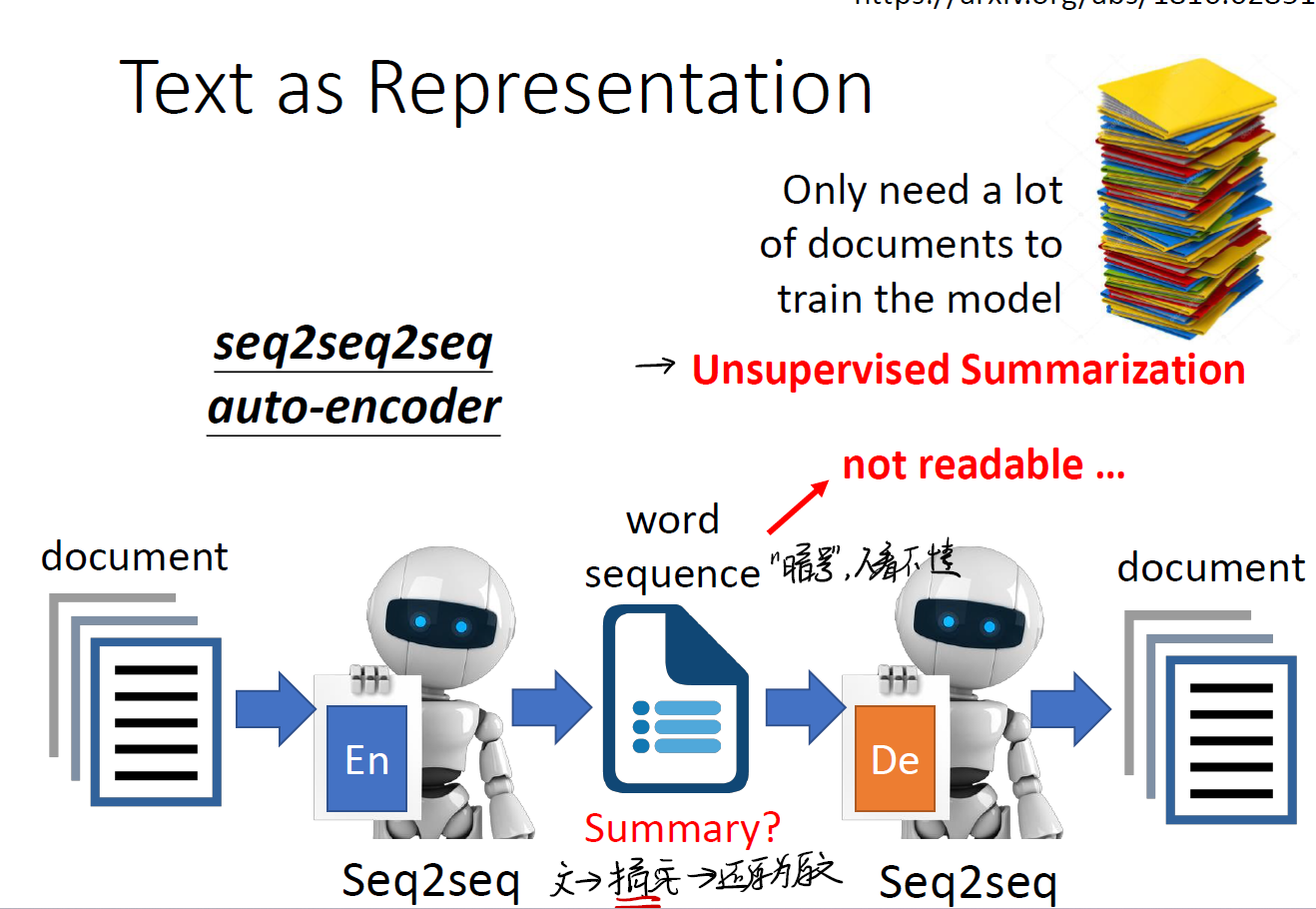
以文本产生摘要为例。
- 在第一阶段,我们通过一个 seq2seq 方法,将文本转化成一个小的 vector ,这包含着了其中的特征信息。可以想象,这就是一个所谓的摘要。
- 第二阶段,我们再用 seq2seq 方法,将这个 vector 还原成文本。
但问题是,这个 vector 我们人类看得懂吗?它是给电脑读的,我们根本无从知道它摘取了什么信息……
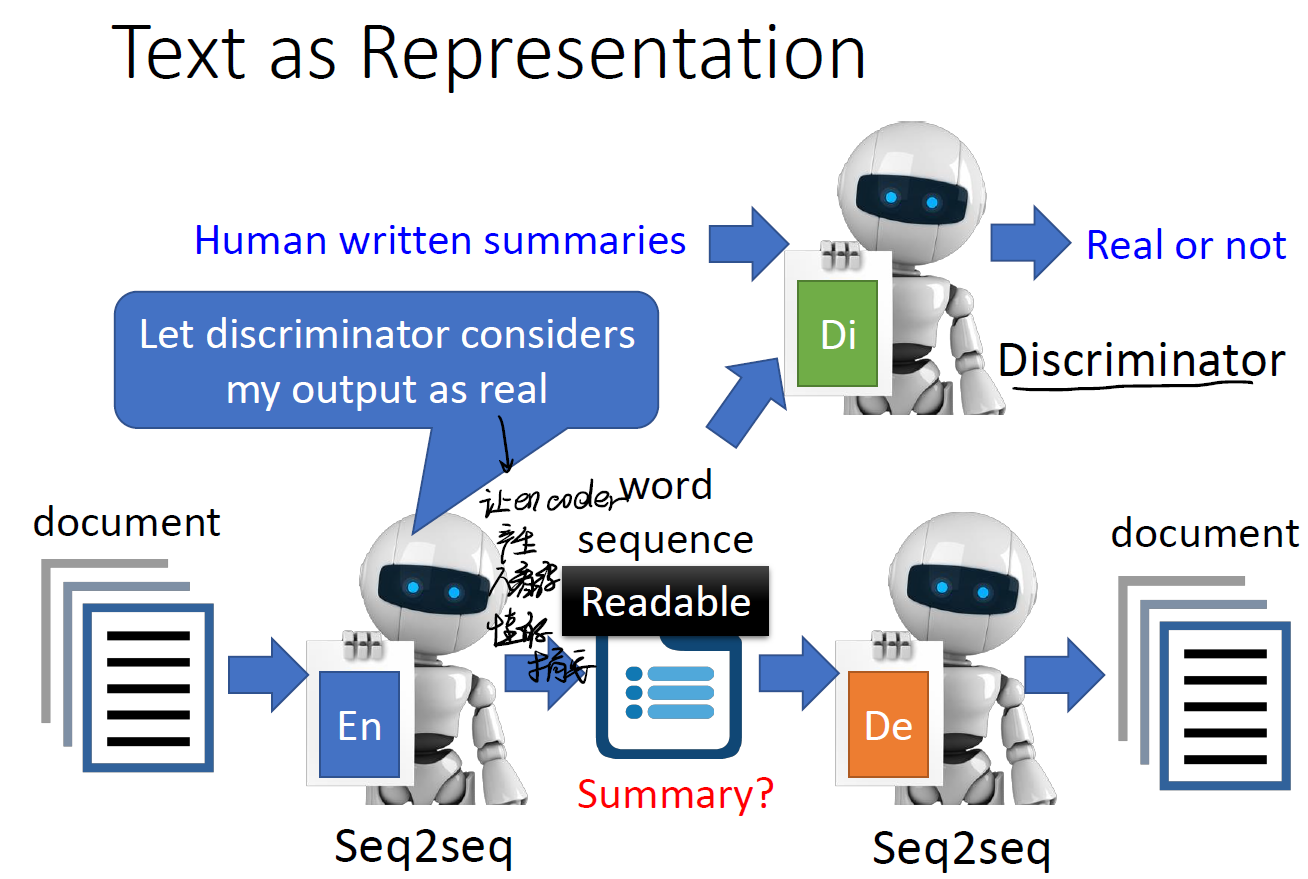
这时候可以借助 GAN 中的方法。引入一个 Discriminator ,让其识别这个 vector 是否能让 Discriminator 误以为是人写的,从而反向训练我们的 encoder ,知道产生人能看懂的摘要为止。
这样,我们就完成了这个任务。
More Applications
Generator
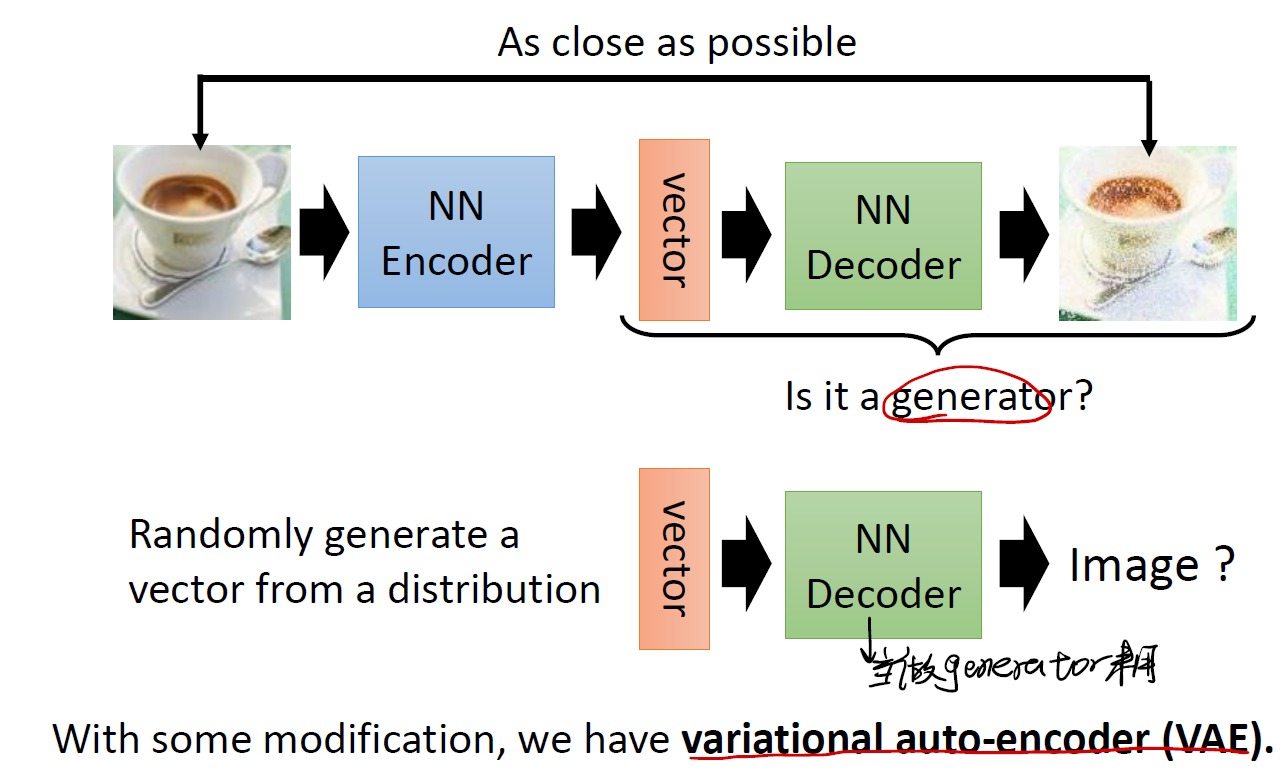
在 Generator 中,我们期望从 encoder 得到的短小 vector 中,产生我们想要的信息(比如一张图片)。
Compression
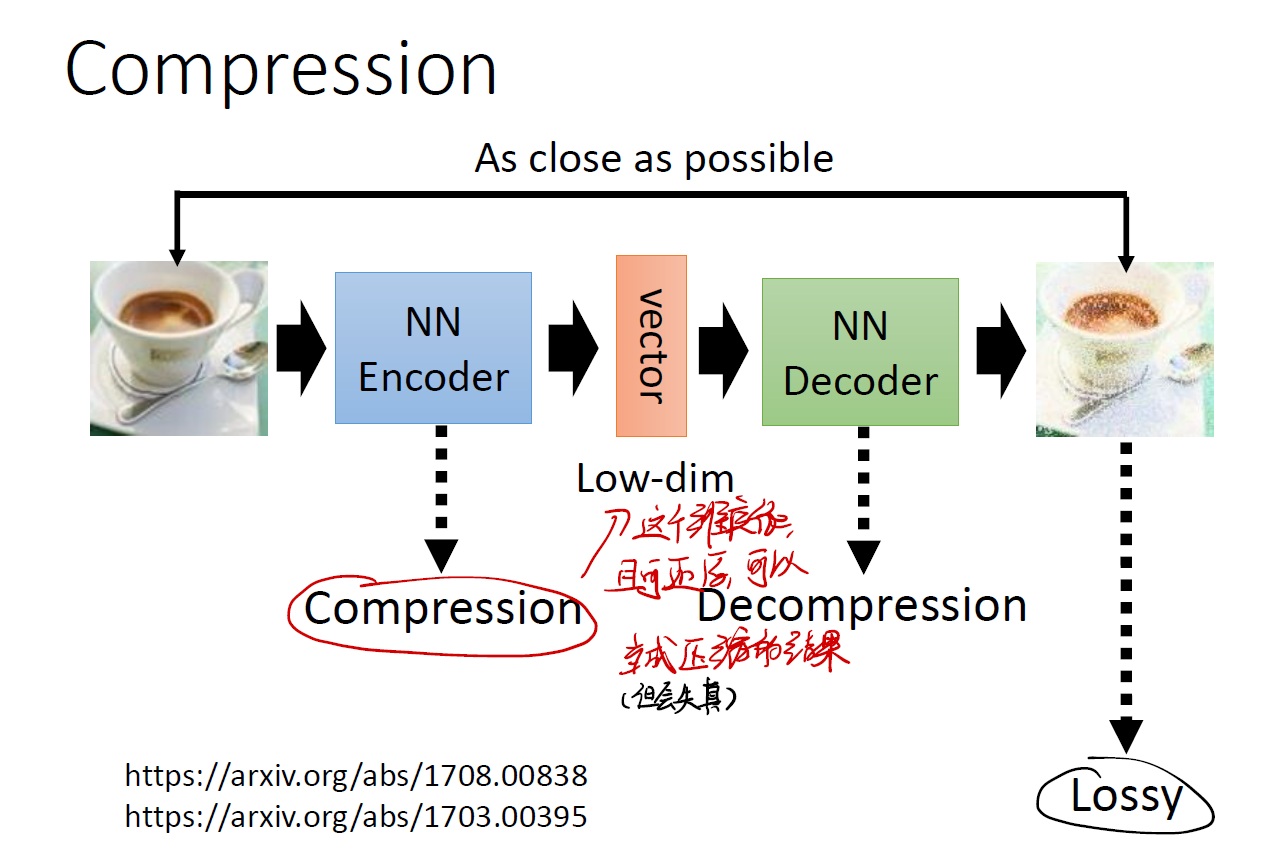
我们已经知道了 vector 有关键信息,这样我们可以用 vector 来代表原先的图片!从而实现一个压缩的任务。这个 vector 在理论上也可以还原成先前的图片。不过很可能会遇到失真的问题。
Anomaly Detection
还可以利用 auto-encoder 完成异常检测的任务。这是我们下一篇的内容。
Reference
本文的图片和 Slides 均来自國立台灣大學李宏毅老师于 2022 年春季学期开设的機器學習课程1。特此对老师表示感谢。
Auto-encoder.pdf: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/auto_v8.pdf ↩︎